Реклама
Да ли верујете у идеју да кад се нешто објави на Интернету, то се објави заувек? Па, данас ћемо разбацити тај мит.
Истина је да је у многим случајевима потпуно могуће искоријенити информације са Интернета. Наравно, постоји запис веб страница које су избрисане ако претражите Ваибацк Мацхине, јел тако? Да, апсолутно. На Ваибацк машини постоје снимци веб страница које се враћају дуги низ година - странице које нећете пронаћи Гоогле претрагом, јер веб страница више не постоји. Неко га је избрисао или је веб локација затворена.
Дакле, нема тога око тога, зар не? Информације ће се заувек уградити у камен Интернета, и то генерацијама које виде? Па, не баш.
Истина је да, иако је можда тешко или немогуће избрисати главне вести које су се прошириле са вести на веб страници или блогу до друге, попут вируса, у ствари је прилично лако потпуно избрисати веб страницу или неколико веб страница из свих евиденција о постојању - уклонити ту страницу са обе претраживачке мреже као и тхе тхе Ваибацк Мацхине
Нова повратна машина омогућава визуелно путовање назад у Интернет времеИзгледа да су од покретања Ваибацк Мацхине 2001. године, власници сајтова одлучили да избаце бацк-енд са седиштем у Алека и редизајнирају га сопственим отвореним кодом. Након спровођења тестова са ... Опширније . Наравно, постоји улов, али ми ћемо доћи до тога.3 начина да уклоните странице блога са нета
Први метод је онај који користи већина власника веб страница, јер они не знају боље - једноставно брисање веб страница. То се може догодити зато што сте схватили да на вашем веб месту имате дупликат садржаја или зато што имате страницу која не желите да се приказује у резултатима претраге.
Једноставно избришите страницу
Проблем са потпуним брисањем страница са ваше веб локације је тај што сте је већ поставили на Нето, вероватно ће бити линкова са ваше сопствене веб локације као и спољне везе са других места до тог одређеног страна. Када га избришете, Гоогле ће одмах препознати вашу страницу као страницу која недостаје.
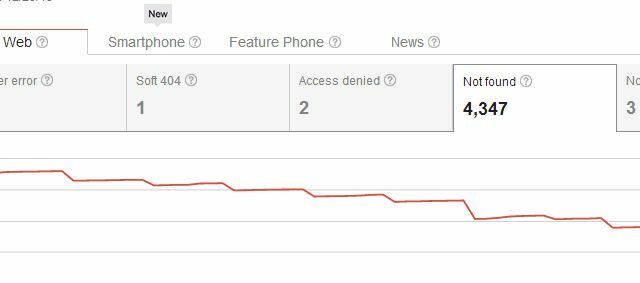
Дакле, брисањем странице не само да сте створили проблем са грешкама у претраживању „Није пронађен“, већ сте створили проблем и свима који су икада повезали страницу. Корисници који на вашу веб локацију стигну преко једне од тих спољних веза видеће вашу страницу 404, што није главни проблем ако користите нешто попут Гоогле-овог прилагођеног кода 404 да бисте корисницима дали корисне сугестије или алтернативе. Али, мислите да би могли постојати елегантнији начини брисања страница из резултата претраживања, а да притом не вратите све 404 на постојеће долазне везе, зар не?
Па, постоје.
Уклоните страницу из резултата Гоогле претраге
Пре свега, требало би да схватите да ако веб страница коју желите да уклоните из резултата Гоогле претраге није страница са ваше сопствене веб локације, онда немате среће, осим ако нема законских разлога или ако је веб локација поставила ваше личне податке на мрежи без ваших дозволу. Ако је то случај, користите Гоогле-ове алатка за уклањање проблема да пошаљете захтев да се страница уклони из резултата претраге. Ако имате ваљан случај, можда ћете успети да уклоните страницу - наравно да бисте могли имати још већи успех контактирање власника веб странице Како уклонити лажне личне податке на ИнтернетуПриватност на мрежи више није гарантована. Сазнајте како пријавити веб локацију и уклонити личне податке са интернета. Опширније као што сам описао како се ради 2009. године.
Ако се страница коју желите уклонити из резултата претраживања налази на вашој веб локацији, имате среће. Све што требате је да створите роботс.ткт датотеку и провјерите јесте ли онемогућили било коју одређену страницу коју не желите у резултатима претраге, или цијели директориј са садржајем који не желите да се индексира. Ево како блокира једну страницу.
Кориснички агент: * Онемогући: /ми-делетед-артицле-тхат-и-вант-ремовед.хтмл
Можете блокирати ботове да претражују читаве именике ваше веб странице на следећи начин.
Кориснички агент: * Онемогући: / садржај-о-личним стварима /
Гоогле је одличан страница за подршку што вам може помоћи да направите датотеку роботс.ткт ако је никада раније нисте створили. Ово дјелује изузетно добро, као што сам објаснио недавно у чланку о структурирање синдикалних послова Како преговарати о понудама за удруживање и заштитити своје листе претраживањаСиндиковање је ових дана бесно. Али одједном сте могли установити да је партнер за удруживање наведен више од вас у резултатима претраге за причу коју сте првобитно написали! Заштитите своје листе претраге. Опширније тако да вам не наудију (молите партнере за удруживање да онемогуће индексирање њихових страница на којима сте удружени). Једном када је мој властити партнер за удруживање пристао на то, странице које су дуплиране са мог блога потпуно су нестале са пописа за претрагу.
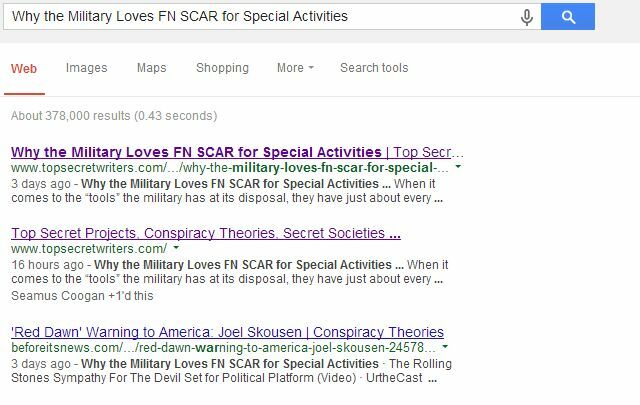
На главном веб месту налази се само треће место на коме се налази наш наслов, али мој блог је сада наведен и на првом и на другом месту; нешто што би било готово немогуће да је веб-локација вишег ауторитета дуплицирану страницу оставила индексирана.
Оно што многи људи не схватају је да је ово такође могуће постићи и са Интернет архивом (Ваибацк Мацхине). Ево редака које морате да додате у датотеку роботс.ткт да бисте је остварили.
Кориснички агент: иа_арцхивер. Онемогући: / узорак-категорија /
У овом примеру, кажем Интернет архиви да уклони било шта у поддиректоријуму узорка категорије на својој веб локацији са Ваибацк Машине. Интернет архива објашњава како то учинити на њиховој страници помоћи за изузеће. Овде објашњавају да „Интернет архива није заинтересована да нуди приступ веб локацијама или другим интернетским документима чији аутори не желе своје материјале у збирци.“
То је супротно увријеженом мишљењу да било шта објављено на Интернету буде померано у архиву заувек. Нопе - вебмастери који поседују садржај могу посебно да уклоне садржај из архиве користећи приступ роботс.ткт.
Уклоните појединачну страницу са мета ознакама
Ако имате само неколико појединачних страница које желите да уклоните из резултата Гоогле претраге, заправо не морате да користите роботс.ткт приступ уопште, можете једноставно додати исправну метаознаку „роботи“ на појединачне странице и рећи роботима да не индексирају или не прате везе на целој страни страна.
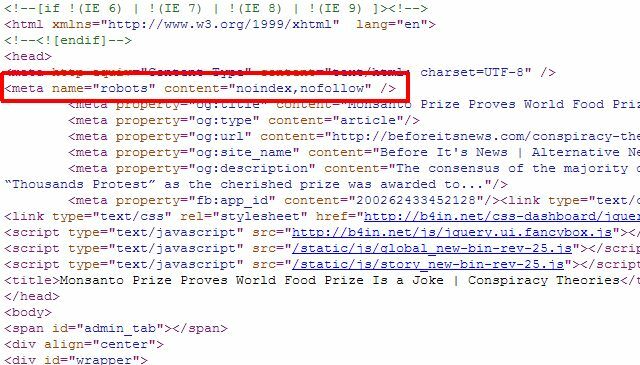
Можете употријебити горњу мета „робота“ да зауставите роботе да индексирају страницу или посебно можете да кажете Гоогле-овом роботу не индексирати тако да је страница уклоњена само из резултата Гоогле претраге, а остали роботи за претрагу и даље могу да јој приступе садржај.
Потпуно је на вама како желите да управљате оним што роботи раде са страницом и да ли се страница наводи или не. За само неколико појединачних страница можда је то бољи приступ. Да бисте уклонили читав директориј садржаја, идите методом роботс.ткт.
Идеја „уклањања“ садржаја
Ова врста окреће читаву представу о "брисању садржаја са Интернета" у својој глави. Технички ако уклоните све сопствене везе до странице на вашој веб локацији и уклоните је из Гоогле претраге и Интернет архивом помоћу роботс.ткт технике, страница је за све намере и сврхе „обрисана“ са Интернета. Супер ствар је, међутим, да ако постоје постојеће везе на страницу, те везе ће и даље радити и нећете покренути 404 грешке за те посетиоце.
То је „њежнији“ приступ уклањању садржаја са Интернета, а да не у потпуности не забринете постојећа веза ваше веб странице на Интернету. На крају, како ћете управљати оним садржајем који прикупљају претраживачи и Интернет архива зависи од вас, али увек запамтите да је упркос ономе што људи кажу о животном веку ствари које се објављују на мрежи, то је заиста у вашој близини контрола.
Риан је дипломирао електротехнику. Радио је 13 година у инжењерству аутоматизације, 5 година у ИТ-у, а сада је Аппс инжењер. Бивши главни уредник МакеУсеОф-а, говорио је на националним конференцијама о визуализацији података и био је приказан на националној телевизији и радију.